
まるクラ勉強会で「Google Cloudでの自然言語処理のアプローチと所感大全(約2年分)」について話しました #まるクラ勉強会
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
機械学習チームのShirotaです。
2024年11月13日(水)に開催された「まるクラ勉強会 ONLINE #03 AWS・Google Cloudを活用した機械学習」にてお話しさせていただいた「Google Cloudでの自然言語処理のアプローチと所感大全(約2年分)」についての資料と、当日お話しした内容についてをまとめました。
本イベントの詳細は以下リンク先をご覧ください。
登壇資料
発表に使った資料は以下になります。
話したこと
以下に、発表の内容をまとめていきます。
業務で主にやってきた自然言語処理の分析
実際に検証・実装し運用してきたもので特に多い分析は、以下の2種類でした。
- 感情分析
- テキスト分類
どちらも、人がこれまで分析して仕分けしてきた文章を自然言語処理を用いて効率良く仕分けるために採用されるパターンが多かったです。
事例にもなっているので、よければこちらもご覧ください。
他には、以下に取り組む機会がありました。
- AI-OCR
- 自然言語処理とOCRを組み合わせた技術領域
- Document AI Workbenchがこれにあたる
- RAG
- 特定のデータを元とした情報検索に特化させる技術
- PDFをデータマートとしてそこに記載されていることを用いたチャットボットの検証
- Vertex AI Agent Builderを使いGUIでチャットボットを構築できる
- エンべディング
- 文章をベクトル化して活用できるようにする技術
- OpenAI Enbeddingを利用してエンべディングしたものをRAGに活用する
ここ最近のLLMの動向

上記にまとめたように、ここ数年でLLM(Large Language Model,大規模言語モデル)は増えて多言語対応・改良を重ねより早く正確に自然な文章を生成できるようになってきました。
Transformerの事前学習済みモデルとして派生したのがBERTとGPTで、BERTはGoogleの検索クエリに採用されています。(2020年の段階で)
よりLLMが近く・使われていると感じられるようになったのは、これらのモデルを実際に触れるようなプラットフォームがここ2年間ほどで増えたからだと思われます。
2022年11月にChatGPTが公開され、2024年2月にはGeminiのアプリも提供を開始しました。
APIも提供されドキュメントの整備も進み、検証のための開発がやりやすくなっていった2年間だったように感じています。
よく構築するアーキテクチャ
Google Cloud上で自然言語処理システムを構築する時によく選ぶアーキテクチャは以下のようになっています。
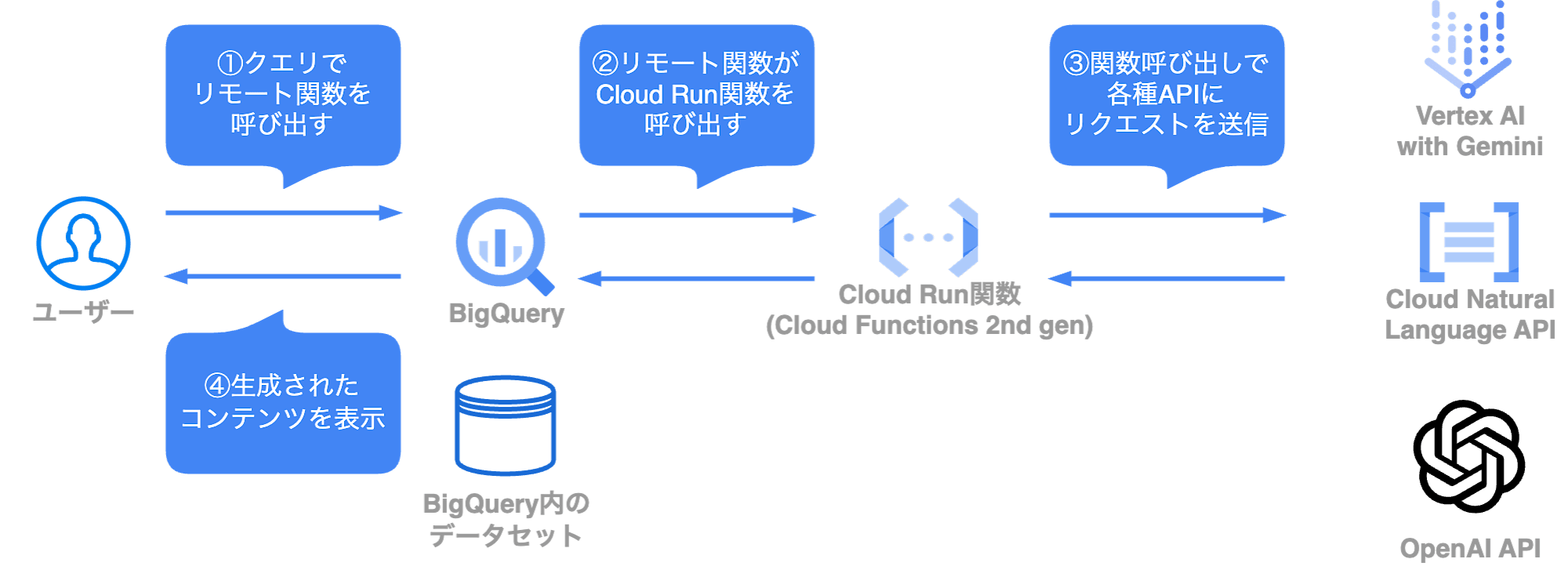
データセットをBigQueryに用意することで、クエリの発行からリクエストとして送信するデータ、帰ってきた出力をBigQueryのGUIで表示することまでを全てBigQuery上で完結させているアーキテクチャです。
構築や運用を担当するチームと実際の分析を担当するチームが異なる時はこのパターンで構築することが多いです。
このアーキテクチャのメリットとしては以下が挙げられます。
- 利用者がBigQuery以外を触ることなく分析を完了・結果を確認することまでできる
- APIを呼び出しに行くところまでアーキテクチャの構成が基本的に共通なので開発速度が早められる
使ってみたいLLMが新しくできて、それがGoogle Cloudのサービス外であった場合でもAPIの提供がされていればこのアーキテクチャを用意すればかなり手軽に検証環境を用意することができます。
もちろん、デメリットもあります。
- マネージドサービス単体の利用と比較するとCloud Run関数の保守が必要になる
- 複数サービスを跨ぐため、それぞれのサービスの権限移譲の把握・制御が増え複雑になりがち
- Cloud Run関数側かBigQuery側、もしくは両方でデータ整形についての処理を書く必要性が出てくる
BigQuery上で完結させることを重視しているため、利用者から見た時にどのようなエラーが起こっているかのハンドリングの設計もある程度作りこんでおく必要がありました。
検証・採用してきたサービスの概要とメリット・デメリット
Cloud Natural Language API
感情分析・テキスト分類含む自然言語処理の事前学習済みモデルを呼び出せるAPIです。
元々は英語のみ対応していましたが、2023年1月に多言語対応したv2(テキスト分類)が一般提供開始となりました。
パブリックプレビュー当時のものですがブログを書いていたのでこちらもよかったらご覧ください。
- メリット
コンソールは提供されていないがcurlや各言語でのソースコードがドキュメントに用意されており、触り始めるハードルが低めになっています。
- デメリット
2023年8月に感情分析含むv2がパブリックプレビューされて以降、アップデートが見られていません。
パブリックプレビューだと一般提供開始した際に仕様が変更されることもあるため、本番環境への適用は基本的に推奨されていません。
また、クラウドサービスはサービス提供終了や他のサービスとの合併が定期的に行われています。
今後の動向が読めない状態になっているといったことがCloud Natural Language APIの現状となっています。
Vertex AI
Google Cloudの機械学習サービスの中でも中核となっているサービスです。
様々なモデル・事前トレーニング済みAPIがModel Gardenに用意されています。
具体的には、先述したGeminiやLLaMA、ClaudeといったモデルやCloud Natural Language APIなどがあります。
また、自前モデルのデプロイや管理・学習・評価までの一連の機械学習ライフサイクルを回すことができます。
- メリット
Google Cloudには元々AI Platformという機械学習サービスがあり、その後継のサービスとしてVertex AIは発表されました。
機械学習の中核サービスであることから開発も活発で新しいサービスや機能が増え続けているので現状ではできなくても今後は使えるモデルや機能が追加される可能性は高いのではないかと思います。
カスタマイズ性も高く自由度が高いので、用意されているマネージドサービスやモデルでは不足している場合にも対応できるところが強みになっています。 - デメリット
カスタマイズ性が高い反面学習コストが増えており、先述したCloud Natural Language APIなどと比較すると使い始めるハードルが少し高くなっていると感じました。
ドキュメントやクイックスタートのようなドキュメントが用意されているのでキャッチアップを継続していく必要があり、またキャッチアップを継続できる運用チームの人員を確保しておく必要があります。
Vertex AI with Gemini
Google Cloud利用者向けに提供されているGeminiです。
Google AI StudioでもGeminiは提供されていますが、こちらは有料プランを利用していないとデータを学習に利用されることになります。
Vertex AIのGeminiは、基本的に明示的な許可を出さない限りはデータを学習に利用されず、社内で閉じておきたい情報を扱う場合に便利です。
GUIのコンソールが用意されており、APIも用意されているので様々なフロントから利用することができます。
APIの利用についてはドキュメントのみでなく、GUIからコードへの出力が可能になっておりより気軽に開発を進めることができます。
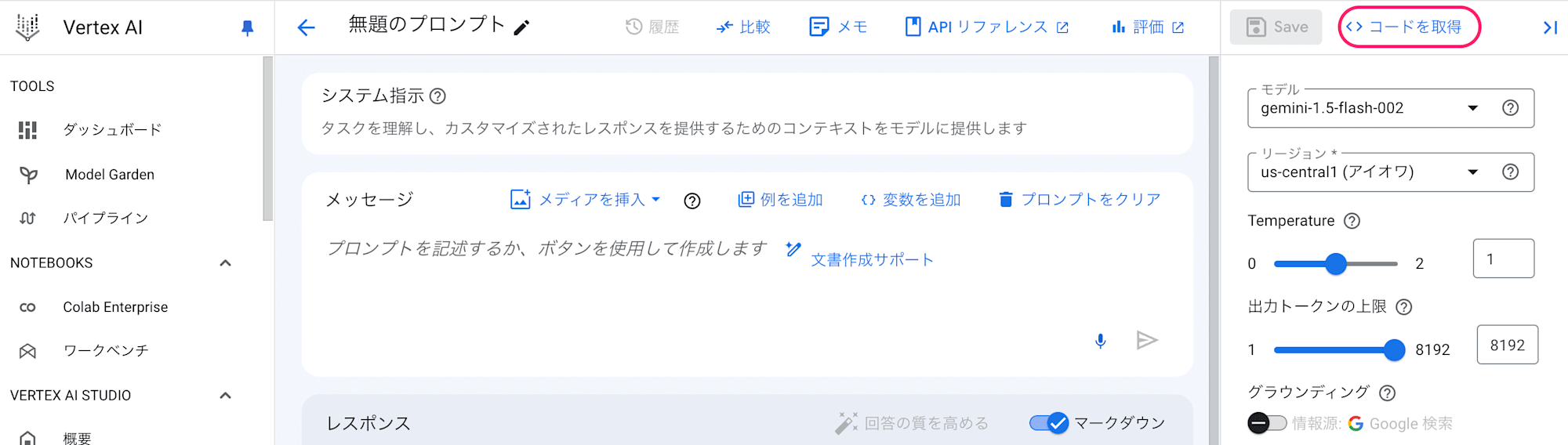
上記の「コード取得」を選択すると、以下のようにGoogle Colabratory(Jupyter NotebookのGoogle提供版)やCloud Run関数で利用できるコードを取得することができます。
- メリット
コンソールにプロンプトを入力してすぐに検証を始めることができる便利さがあります。
また、先述の通りプライバシーの保護やGoogle Cloud上のGeminiということもありセキュリティは堅牢になっています。
APIの利用リクエスト数などの制御や予算の設定など、細かな管理ができることも嬉しいです。
Gemini自体が大きなトークン数への対応をしていたりレスポンスが早いことも個人的にはおすすめできるポイントです。 - デメリット
出力の仕様がコンソールとAPIで共有なので、コンソール出力に合わせたマークダウン形式の出力がされます。
出力データを加工したりJSONを整形して利用したい場合、整形の処理は自分で書いて実装する必要があります。
BigQuery ML(BQML)
BigQuery上からクエリを利用して機械学習モデルの作成や学習、各種APIを実行することができます。
GeminiやCloud Natural Language APIを呼び出すこともできるようになっています。(2024年11月現在)
- メリット
よく作るアーキテクチャで紹介したアーキテクチャを用意することなく、同じようにBigQuery上で完結することができます。 - デメリット
別のサービスから呼び出せるモデルやAPIが多いので、BQML用のクエリのお作法を学習するよりもよそから呼び出したほうが楽な時もあるように感じました。
まとめ
ここまで各種サービスについて見てきましたが、ここ数年で様々なアーキテクチャの選択肢が増えてきたように思われます。
生成AIの文脈でより強化されたLLMが発表されたり、日本語LLMの開発も盛んになってきているようです。
どうしても運用の簡潔さを重視したマネージドサービス単体の利用とカスタマイズ性をとった各種サービスを連携した環境とではそれぞれメリット・デメリットが異なり、トレードオフを検討しなければならない場面も出てくるでしょう。
状況は刻々と変わっていくので、その時々の情報収集を欠かさず行い適したサービスを考えていくことが大切になるのではないかと思います。
当日いただいたご質問への回答
勉強会の中で回答させていただきましたが、改めてこちらにも記載しておきます。
ご質問ありがとうございました!
全くGoogleCloudに知識がなく素人質問で恐縮ですが、AWS/AzureではなくGooggle Cloudが選択肢に上がってくるのはどのようなシーンでしょうか?データ基盤ではGoogle Cloudが使われているイメージです。
ご質問者様もイメージされているように、Google Cloudをすでにデータ基盤として採用しているプロジェクトは多いように見受けられます。
理由としては、データ基盤として採用されがちなBigQueryがデータウェアハウスとして柔軟性が高くGoogle Cloudの様々なサービスと連携することでデータ分析アーキテクチャとして多岐に渡る使い方ができるためだと考えております。
BigQueryを利用していると、BigQuery MLや先述のよく構築するアーキテクチャでも紹介したように機械学習サービス含め様々なGoogle Cloudのサービスを繋ぎこむことが楽に実現できます。
また、すでにGoogle Cloudと契約をしていることもあり各種サービスを使い始めるためのハードルは低くなっているのではないかと思います。
逆にAzure・AWSを利用している場合は各クラウドサービスの機械学習サービスとデータ基盤を繋ぎこむ方が楽だと考えております。
そのような状況でGoogle Cloudの機械学習サービスを利用したい場合は別途マルチクラウドソリューションを検討してみるのも良いのかもしれないです。










